
Prompt Engineering I Didn't Know I Was Doing
A StarEast tutorial put names to prompt engineering techniques I was already using and filled in gaps with a practical prompt template for test engineers.
Tariq King opened his StarEast 2026 prompt engineering tutorial with a critique rather than a definition. The "ten best prompts for your discipline" content that flooded the internet after ChatGPT's release was, in his view, the wrong way to teach it. "This space is moving too fast for there to be ten just best prompts for any discipline," he said. His alternative was teaching pattern thinking (recognizing familiar structure in new problems) on the theory that testers already have the instincts for it. By the end of the day I realized he was at least partly right about me, though perhaps not in the way he intended.
King is VP of AI for Quality Engineering at EPAM and a former colleague from my time at Ultimate Software (now UKG). He uses a four-stage framework for thinking about prompt engineering techniques: Guiding, Shaping, Refining, and Formalizing. By the time he walked through it I had recognized several techniques I had been using without a name, encountered a few I had heard of but never applied deliberately, and picked up at least one I had never tried. Together they covered both goals I had for attending StarEast: confirmation that the AI prompting approaches I had already been using were on the right track, and awareness of what I had not yet tried.

Pattern Thinking, Not Prompt Libraries
The session's central argument was about how you learn prompting rather than what prompts to memorize. King's position: no fixed set of prompts survives contact with a fast-moving AI landscape, so memorizing a prompt library trains the wrong habit. What transfers across tools and model updates is pattern thinking, which he defined as "recognizing commonalities between a problem and similar problems that you've already faced, and then applying your past experiences to what you know as a new set of circumstances, even if they don't exactly look the same."
For me, this is like how early antivirus programs would look for an exact signature for computer viruses, but they were evolving and changing so often that keeping the definitions up to date became impractical, so they started to employ heuristics or pattern matching to look for virus-like behavior rather than exact fingerprints.
He illustrated pattern thinking through a few anecdotes in his personal life solving them at the pattern level. For example, one pattern he identified was that his wife liked to unwind late at night by browsing Amazon on her laptop with the credit card beside her. He recognized this pattern led to late night impulse shopping and getting daily Amazon packages. His solution was hiding the laptop at night.
King stated:
So pattern thinking is where you're recognizing commonalities between a problem and similar problems that you've already faced, and then you're going to apply your past experiences to what you know as a new set of circumstances, even if they don't exactly look the same.
Testers are, he argued, already wired for this. The habit of asking what could go wrong, what edge cases exist, what the system is not being told, maps directly onto the habit of recognizing when a prompt is missing something.
That connection landed immediately for me. It's exactly the sort of thing I do when shifting left to test requirements during Agile story kick-off sessions, catching ambiguity before it reaches development. People naturally fill in information gaps with their best interpretation of what was intended, and so do language models. Underspecified requirements produce the wrong feature. Underspecified prompts produce the wrong output.
The four-stage framework he then taught is built to exercise that instinct deliberately and provide a vocabulary for what you are likely already doing informally.
This reminded me of when early in my testing career I was already applying boundary value analysis and equivalence partitioning before I knew those were the names for them. Learning the vocabulary did not change the instinct; it made it easier to learn more about, teach, and apply deliberately.
Guiding: Zero-Shot, Few-Shot, and Role-Based Prompting
The first stage covers five techniques for how you initiate an interaction:
- Command
- Query
- Completion
- Conversation
- Personas
Command and Query are the ones most people discover through iteration without naming them. A command is directive ("create a recipe for a delicious hamburger"). A query produces options ("what are some popular recipes for hamburgers?"). The outputs have meaningfully different shapes, and choosing between them deliberately (rather than defaulting to whichever phrasing comes naturally) is itself a prompt engineering technique. Knowing the name and that they are distinctive patterns lets you be more intentional about which one you pick and when.
The Persona technique, more commonly called role-based prompting, came with a nuance most tutorials skip. King noted both names for it: "the persona pattern... a better, more formal name for this is role-based prompting." Assigning the model a role alone does not reliably change the depth or tone of its output. You also need to specify who the response is for. "If you say that you are a PhD in whatever, it may not come back to you just because it doesn't think that you're the PhD who is answering the question too. But if you say, hey, I am a PhD student who's trying to learn something, I need to find information about this, then it can use that in your response." The practical version of this he demonstrated was asking the model to act as a Tesla enthusiast while he played a competing EV salesperson preparing to pitch to that customer. The persona works because both roles are specified.
Before attending the session I only equated the persona technique to the "Pretend you are an expert in impressionist paintings..." sort of role-play. Separately, I had been using the audience shaping persona technique to shape the response with prompts like, "Let's create a defect analysis report, the audience are executives not familiar with QA jargon." to help shape the response into one that matched the intended audience.
Zero-shot and few-shot prompting also live in Guiding. Zero-shot means providing no examples; few-shot means providing one or more.
The guidance for when to use each is:
- Skip examples for tasks the model handles well by default (translation, summarization)
- Provide examples for domain-specific work
King stated, "One of the things that I normally do before any kind of test generation is I provide guidelines on how I want it to generate things and I provide example tests." This applies immediately to testing workflows, and it connects forward to the Formalizing stage in a way that only becomes apparent later in the day.
I do the same. For example, when having Claude co-author tests I'll have it use a known good suite as an example to help prevent style drift from session to session.
Shaping: Tightening the Prompt
Shaping covers techniques for narrowing and correcting the model's context after the initial Guiding exchange. The three with the most practical weight in the session were Pre-Heating, Overriding, and Tweaking.
Pre-Heating is the technique of starting broad before narrowing to your actual topic. The rationale is that starting broad keeps you in command of a subject you can partially validate before trusting the narrower output you actually need. "You should be able to validate the results" from the broad question before relying on the specific one.
King demonstrated it using his daughters as context:
Step 1 — Start broad:
"Tell me about some of the dangers of letting children use the internet."
Step 2 — Narrow based on the response:
"Based on the above list, create customized checklists to keep my 8 and 12-year-old daughters safe from online predators and cyberbullying."
Again, this is something I'd instinctively do, but never had a name for. Naming it and understanding why it works (you are staying in an auditable position before letting the model get specific) turns a habit into a deliberate choice. I must have told at least 3 people separately and one larger group about this session take-away. I had never given it a name before.
Overriding addresses the problem of AI context memory being hard to erase. King demonstrated the problem by opening a fresh chat window, asking about "testing," and getting software testing back — prior conversation history was silently shaping the response in ways that aren't obvious. "There's many times that you open this window and you asked about something and you weren't thinking about what historical conversations you had in that context before."
His solution was a direct context reset: a prompt along the lines of "forget everything we've talked about regarding ___" to clear the model's context around a specific subject before continuing. He also noted the incognito-browser approach as a harder reset, with the tradeoff that you lose paid-tier features in an unauthenticated session. The memorable framing for why the model resists a clean slate: "It doesn't want to forget you. It wants your $20 a month."
Prior to the session the only active solution I'd use to clear state if things got off track would be to launch a new Claude terminal. I hadn't considered using a prompt to erase the context around a subject explicitly.
Tweaking covers what most practitioners do naturally during iteration: noticing that the output has an unwanted pattern and tightening the prompt to correct it. King's exercise used fake test data generation. The class noticed the generated addresses skewed toward Florida zip code prefixes despite no location being specified, which he flagged as an example of model bias worth knowing about. "When you notice a pattern of behavior that you don't really like, or that you want to change, you can just tweak your prompt a little bit." The progression from "I want to generate fake names and addresses for test data purposes" to "Generate 10 fake names and addresses. Make sure they are global. And I don't want any kind of chatter" is what that looks like in practice.
Refining: Pyramid and Chain of Thought Prompting
The Refining stage covers two techniques: Pyramid and Chain of Thought.
The Pyramid is a drill-down pattern for open-ended research: start with a broad question, narrow into a sub-area, then narrow again to the specific thing you care about. The name made more sense once I flipped it — picture a funnel instead, wide at the top for the opening question and narrowing as you go deeper. King's adversarial testing example shows the path:
"Tell me about AI security. Tell me some of the different patterns for AI security." → then narrow to adversarial testing of neural networks specifically.
The return trip is just as important. Once you've explored a specific area, you can widen back out and narrow into a different branch of the same broad topic. King described this with a test data management example: "If you know that you're going to be looking at test data management... it makes sense to start that pyramid conversation and then just move up and down the pyramid as you see fit in that very large area."
King described it as "not a big deal" to grasp, and he was right. Most people do this instinctively when researching something new. What naming it provides is a deliberate structure for a session you might otherwise wander through.
Chain of Thought prompting asks the model to reason step by step rather than jump straight to an answer. King's Belgium trip example shows the difference. A prompt like "I am going to be planning a trip to Belgium. Can you help me?" tends to produce prose — a few sentences of general advice. Rephrase it to reason through the planning step by step and the output shifts: instead of a paragraph summary, you get a hierarchy of preparation stages, each one broken down. The model shows its work rather than summarizing it, which gives you something to audit and correct at each step.
Of the four stages, this is the one that resonates least with me personally. It may be that I tend to use thinking models by default, and CoT is already baked into how they operate. Or it may be that the specificity I try to build into my prompts from the start is already doing some of the same work — a detailed, structured prompt leaves less room for the model to take a shortcut to an answer. Either way, I don't find myself reaching for it explicitly.
King covered it for completeness: "Not everyone is using a model that has reasoning built in. And therefore, for completeness, we should still make sure we cover it." The technique traces back to early LLM math failures — models got arithmetic wrong, and the fix was combining few-shot examples with an explicit step-by-step instruction. The one tradeoff worth knowing: more steps means more surface for tangents. "Sometimes they go down a rabbit hole."
Formalizing: The Payoff
The fourth stage is where the session got most interesting for me, and it connects back to the zero/few-shot observation from Guiding in a way I did not expect.
King described Formalizing as the process of treating prompts as persistent artifacts rather than one-off inputs: versioned, reviewed, and stored in something like a prompt library (a term that means something more structured here than the "ten best prompts" type he criticized in the opening hour). The practical centerpiece was a markdown template structure he uses at EPAM for building production-grade prompts.
# Mission/Goal
# Context
# Input/Examples
# Guidelines
# Output Format
# Request
The Request heading functions as a placeholder for a ticket or feature requirement ID, tying the prompt to whatever task drove it.
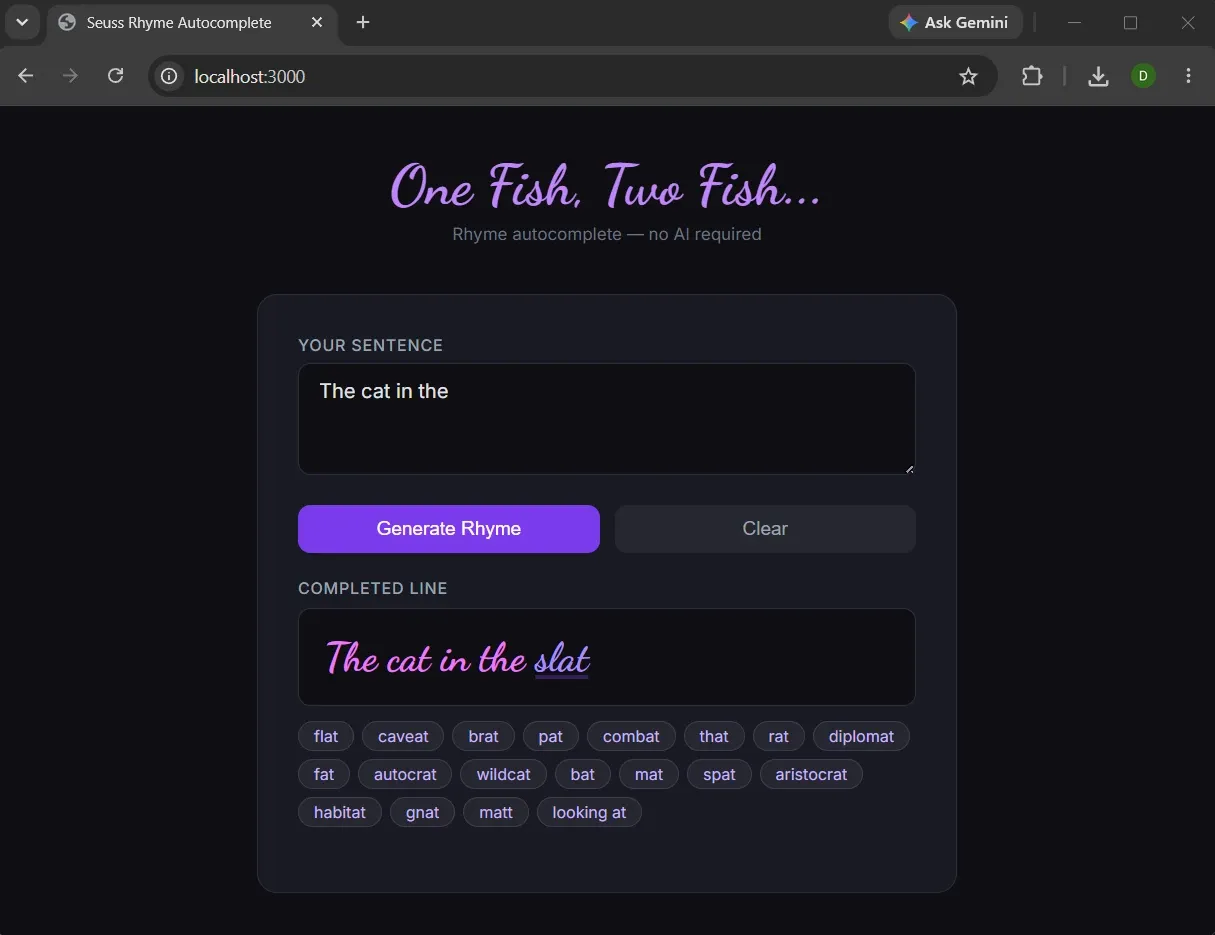
To show the effectiveness of formalizing in practice, King asked us to use this template to build our own apps in class as a hands on activity. The template was close enough to the structure I was already using that I chose to adapt some of his wording rather than follow it verbatim. I decided to make something that was a take on one of the opening slides he presented about how large language models are trained showing context examples like "The cat likes to sleep in the " where it predicts the next word. I didn't have an AI API key to use AI generative features so I had to constrain the prompt to, ironically, not use AI for the app I was asking it to build. The prompt I wrote:
# Goal
I want to create a web app that lets a user enter a sentence or sentence fragment and it autocompletes the best it can without using generative AI the next word or words to complete a rhyme.
# Requirements
It should be a Node.js app using the simplest way of doing a quick and dirty self-hosted prototype since this is for a time-limited tutorial class.
- There should be a labeled text box for user input
- There should be a fancy-font formatted output of the completed sentence
- The color scheme should be dark mode
- Clear input button
- Generate output button
# Guidelines
- Don't use AI
- Use rhyming libraries since we don't have an API key
# Input Output Examples
`The cat in the ` -> `hat`
`My dog laid down on the ` -> `mat`
# Output Format
Given the two examples from earlier we should have a fancy cursive-like formatted text element on the page
I had landed on a similar structure on my own because structured prompts for multi-part tasks produce better results — and when you're trying to get something specific out of a complex ask, you naturally start reaching for labeled sections (at least that's how I organize my thoughts). What the EPAM template adds is standard vocabulary (Mission/Goal rather than just Goal, Input/Examples as a named section) and the Context and Request fields I had not included. Real gaps.
Let's talk about the app I made in the compressed time we had in class. Giving it the guideline "Don't use AI" at runtime was an ironic, but necessary constraint given I wasn't armed with a Claude API key in class. The result was a dark-mode Node/Express rhyme-autocomplete app (titled "One Fish, Two Fish...") that uses the offline rhymes package backed by the CMU Pronouncing Dictionary rather than any API call. The few-shot examples from the Guiding section showed up directly in the prompt as input/output pairs ("The cat in the " → hat; "My dog laid down on the " → mat), providing the domain-specific examples that the zero/few-shot guidance said to always include. The Formalizing stage's template, the Guiding stage's few-shot advice, and the hands-on project all pointed at the same thing from different angles.
One item King listed on the Formalizing slide without covering during the session is worth a brief note: Delimitation. In prompt engineering, delimitation refers to using explicit separators (triple backticks, XML tags, or markdown section headers) to make the boundaries between sections of a complex prompt unambiguous to the model. If you look at the EPAM template above, the # headers are delimiters. The technique was implicit in everything the Formalizing stage covered. It just did not get its own explanation on the day.
King closed with a note on terminology: he does not love the phrase "prompt engineering" and prefers to think of it as crafting, the way testers craft test cases. Engineering requires skill, and what skilled practitioners produce is, in a meaningful sense, crafted. The two terms describe the same activity from different vantage points, and the rest of the session made a reasonable case that the activity, whatever you call it, benefits from the same discipline you would apply to any other artifact you intend to maintain. Personally, I still prefer engineering since crafting feels like it belongs for sale on Etsy instead of a professional context.
When the Prompts Start Acting
The final section of the tutorial moved from individual prompting habits to what happens when those habits operate at scale. The prompts you write today are increasingly becoming the instructions that autonomous agents act on directly: checking code into repositories, updating issue trackers, writing to production systems. King states, "These prompts that you built, really do kind of do things at the task level, what these are becoming are the basis for autonomous agents... those agents are actually being equipped with tools to interact with them. So they're checking things in to the repository, they're pushing things to your case management system, they're going to Jira updating things."
He described, without naming it, a company that had (in his words) "effectively wiped itself out" through agent-executed actions that were not adequately reviewed before running.
This connects directly to something Andy Knight argued in the prior StarEast tutorial on Playwright and AI. Knight's framing was that AI-generated test code functions like compiled output: you pay the human review cost once at generation time, then run something fast and cheap indefinitely. That model assumes the review actually happens. King's agents risk argument is the case study for what occurs when it does not. Two sessions, two different technical domains, converging on the same guardrail: AI output earns trust incrementally, through review, not by default.
King's prescription follows naturally from the testing mindset. "In testing, we deal with risk all the time." The same graduated trust you apply to a new colleague's pull request applies to an agent operating on your behalf. "It starts with kind of getting into that groove of understanding that you don't fully trust the machine for everything. There's some level of trust that will build up. You'll see it working well for certain things, but you're still checking to some degree."
Takeaway
The framework King teaches is not a prompt library, which is exactly his point. Guiding, Shaping, Refining, and Formalizing are a vocabulary for what practitioners tend to develop informally over time, made explicit and teachable.
What surprised me was how much of it was already in my workflow without a name. The Tweaking, the Pre-Heating, the few-shot examples in test generation guidelines. The session's value was not in replacing those habits but in naming them, connecting them to a structure, and filling in the gaps I had not noticed. The EPAM markdown template is the practical artifact to take away if you are writing prompts regularly and want to start treating them as something worth maintaining. The pattern thinking argument is the reason it matters: the prompts you formalize today are the instructions your agents will act on tomorrow.
For more context on the conference week: the other StarEast tutorials I attended covered AI vision testing and Playwright MCP, hands-on AI tooling and evals, and cost-efficient Playwright testing with AI assistance.